WildCap: Facial Albedo Capture in the Wild
via Hybrid Inverse Rendering
CVPR 2026



Overview
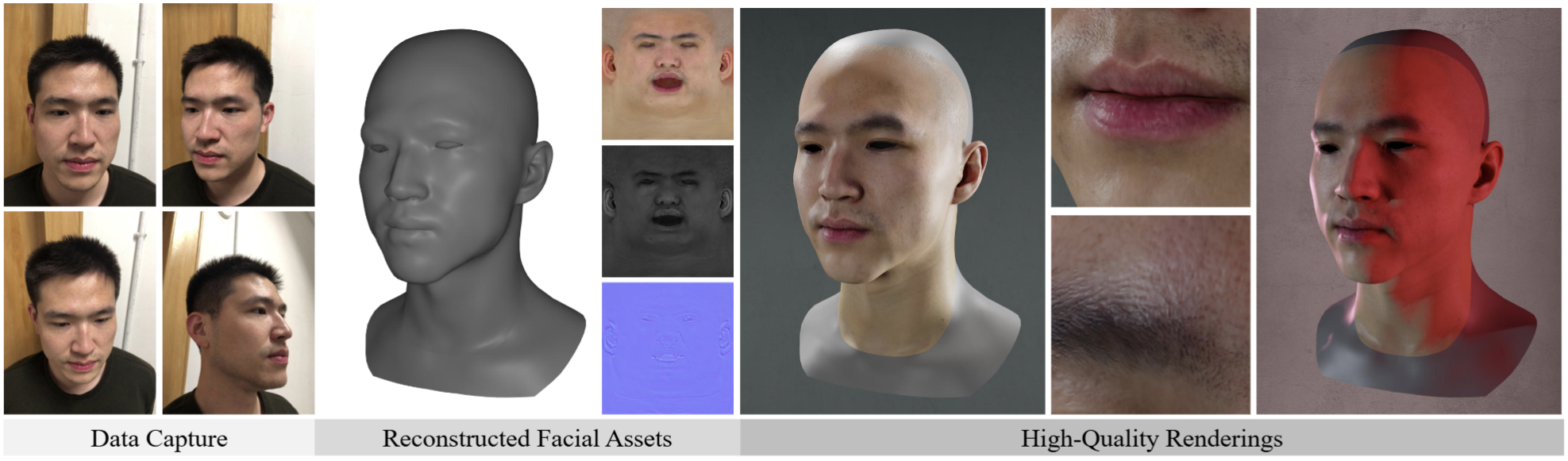
We propose a novel method for low-cost high-quality facial appearance capture.
Given a single smartphone video captured in the wild (a big improvement of our previous work CoRA and DoRA), our method can reconstruct high-quality facial assets, which can be exported to common graphics engines like Blender for photo-realistic rendering.
As shown in the figure above, our method can faithfully reconstruct detail patterns on different facial regions.
My personal views on the task of "Facial Appearance Capture in the Wild" (these views are solely my own and do not represent those of my collaborators or affiliated institution):
-
The main challenge: I believe the biggest challenge is to disentangle shadows from the albedo in order to obtain a clean diffuse albedo map.
-
Why optimization-based inverse rendering methods fail to handle shadows well: Optimization-based inverse rendering requires a strong illumination model to explain the shadows in the input image. If the shadows on a human face are cast by near-field lighting (e.g., ceiling lights), the infinitely distant environment lighting model cannot account for such shadows. However, the illumination models supported by current differentiable renderers are relatively limited.
-
How to properly handle shadows: At this stage (2026), using data-driven methods for shadow removal is the most feasible approach. In the future, if optimization-based methods advance (with stronger illumination models, higher efficiency, and more stable convergence), we can also consider optimization-based methods for shadow removal.
-
-
The main goal: In my opinion, solving for the diffuse albedo map is the core goal.
-
On the one hand, with high-quality diffuse albedo, we can train a neural network to predict other reflectance maps (such as specular albedo, normal, and roughness) from the diffuse albedo. Although these predicted maps may not match the true physical properties of the human face, they still produce good rendering results, since most of the identity information is contained in the diffuse albedo.
-
On the other hand, reconstructing accurate parameters such as specular albedo and roughness requires observing specular highlights on the human face (see Ravi Ramamoorthi's paper for more details). However, we focus on the in-the-wild setting: user-captured data may be acquired under either low-frequency or high-frequency lighting. For low-frequency lighting, it is of course difficult to recover accurate specular and roughness parameters from the input data. For high-frequency illumination, in theory we can only estimate these parameters in regions where highlights are visible, while prediction is still required for non-highlight regions. Since highlight regions typically occupy only a small portion of the face, it is questionable how much advantage such an approach actually offers over pure prediction in terms of improving fidelity.
-
See our video for more illustrations and results:
Citation
@inproceedings{han2026wildcap,
author = {Han, Yuxuan and Ming, Xin and Li, Tianxiao and Shen, Zhuofan and Zhang, Qixuan and Xu, Lan and Xu, Feng},
title = {WildCap: Facial Albedo Capture in the Wild via Hybrid Inverse Rendering},
booktitle = {CVPR},
year={2026}
}